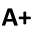
id: observation identifier.
t1: measurement on test 1; t2: measurement on test 2.
t3: measurement on test 3; t4: measurement on test 4.
t5: measurement on test 5; t6: measurement on test 6.
t7: measurement on test 7; t8: measurement on test 8.
d: binary output variable set to 1 if product is defective and 0 otherwise.
The next 600 lines contain 600 examples, for which the values of the above features are specified.
The table below reproduces the first 2 observations.
|
id |
t1 |
t2 |
t3 |
t4 |
t5 |
t6 |
t7 |
t8 |
d |
|
1 |
17 |
3 |
31 |
54 |
66 |
54 |
45 |
84 |
1 |
|
2 |
2 |
15 |
6 |
5 |
82 |
54 |
59 |
87 |
1 |
· Use rpart with the training examples to come up with a small set of rules that correctly classify the output variable “d” based on input variable values (t1, t2, t3, t4, t5, t6, t7, and t8).
· Specify the rules.
· The file “dt_test.csv” contains 200 test examples with the same 10 variables. Test your trained classifier on these test example and present your confusion matrix. Comment on your classification accuracy.
·
Then use
the rules to predict the output class d for the following ![]() test cases (presented in the
file “dt_new.csv”):
test cases (presented in the
file “dt_new.csv”):
|
new_case |
t1 |
t2 |
t3 |
t4 |
t5 |
t6 |
t7 |
t8 |
d |
|
1 |
8 |
86 |
55 |
53 |
36 |
12 |
82 |
19 |
|
|
2 |
22 |
36 |
80 |
69 |
90 |
33 |
22 |
6 |
|
|
3 |
74 |
26 |
32 |
26 |
38 |
52 |
63 |
12 |
|
|
4 |
66 |
71 |
71 |
52 |
42 |
88 |
89 |
70 |
|
|
5 |
55 |
72 |
61 |
41 |
91 |
39 |
50 |
96 |
|
|
6 |
34 |
58 |
22 |
84 |
84 |
61 |
95 |
57 |
|
|
7 |
23 |
70 |
39 |
65 |
16 |
71 |
96 |
78 |
|
|
8 |
9 |
19 |
67 |
43 |
2 |
20 |
92 |
3 |
|
|
9 |
6 |
71 |
20 |
6 |
27 |
58 |
6 |
22 |
|
|
10 |
68 |
40 |
86 |
82 |
82 |
44 |
61 |
48 |
|
